Coroutine Context and Scope
Different uses of physically near-identical things are usually accompanied by giving those things different names to emphasize the intended purpose. Depending on the use, seamen have a dozen or more words for a rope though it might materially be the same thing. (Wikipedia on Hindley-Milner type system)

Every coroutine in Kotlin has a context that is represented by an instance of CoroutineContext interface. A context is a set of elements and current coroutine context is available via coroutineContext property:
Coroutine context is immutable, but you can add elements to a context using plus operator, just like you add elements to a set, producing a new context instance:
A coroutine itself is represented by a Job. It is responsible for coroutine’s lifecycle, cancellation, and parent-child relations. A current job can be retrieved from a current coroutine’s context:
There is also an interface called CoroutineScope that consists of a sole property — val coroutineContext: CoroutineContext. It has nothing else but a context. So, why it exists and how is it different from a context itself? The difference between a context and a scope is in their intended purpose.
A coroutine is typically launched using launch coroutine builder:
fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
// ...
): JobIt is defined as extension function on CoroutineScope and takes a CoroutineContext as parameter, so it actually takes two coroutine contexts (since a scope is just a reference to a context). What does it do with them? It merges them using plus operator, producing a set-union of their elements, so that the elements in context parameter are taking precedence over the elements from the scope. The resulting context is used to start a new coroutine, but it is not the context of the new coroutine — is the parent context of the new coroutine. The new coroutine creates its own child Job instance (using a job from this context as its parent) and defines its child context as a parent context plus its job:
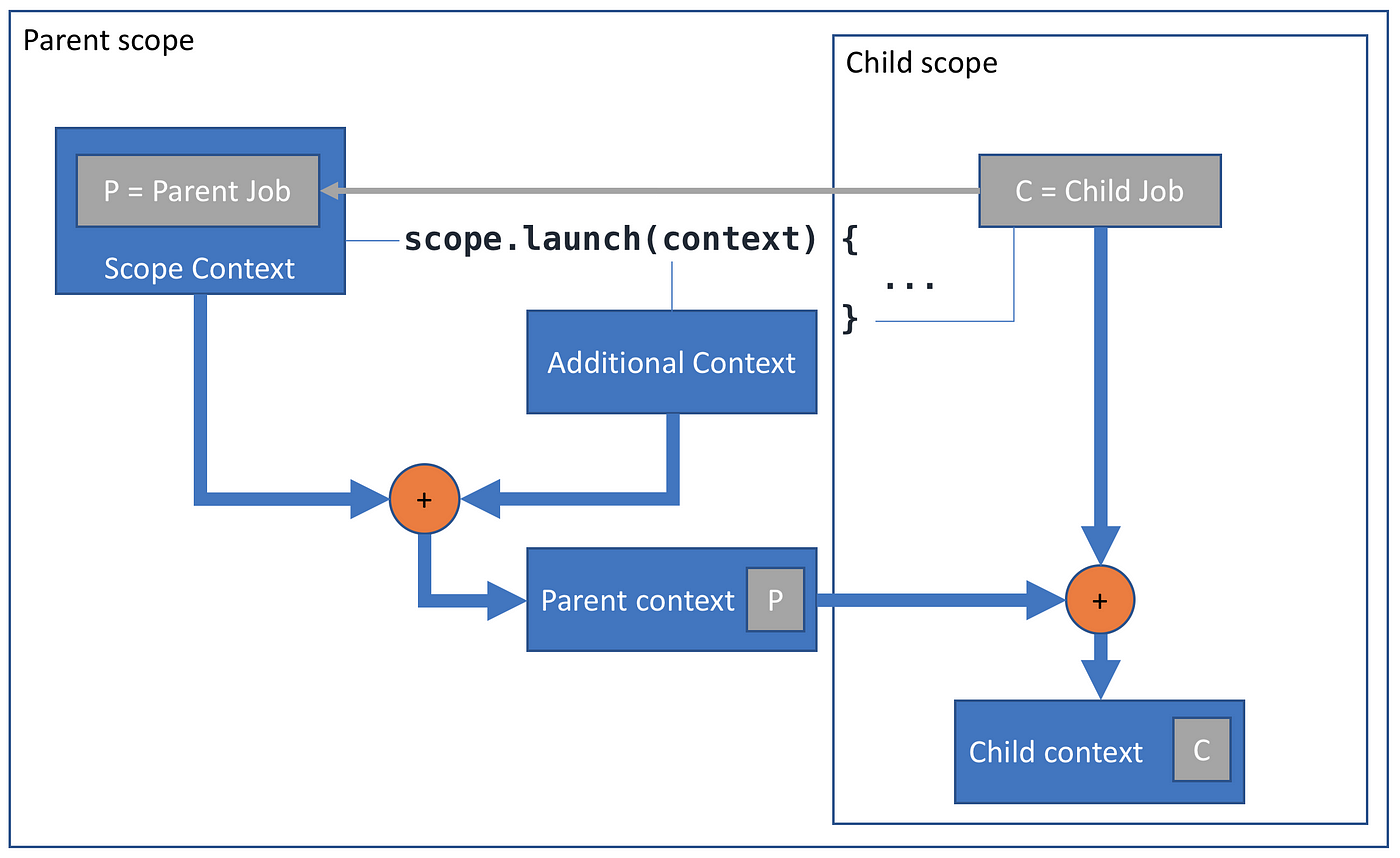
The intended purpose of CoroutineScope receiver in launch and in all the other coroutine builders is to reference a scope in which new coroutine is launched. By convention, a context in CoroutineScope contains a Job that is going to become a parent of new coroutine (with the exception of GlobalScope that you should avoid anyway¹).
On the other hand, the intended purpose of context: CoroutineContext parameter in launch is to provide additional context elements to override elements that would be otherwise inherited from a parent scope. For example:
By convention, we do not usually pass a Job in a context parameter to launch, since that breaks parent-child relation, unless we explicitly want to break it using a NonCancellable job, for example.
Notice, that a block of code inside launch is defined with CoroutineScope as its receiver:
fun CoroutineScope.launch(
// ...
block: suspend CoroutineScope.() -> Unit
): JobBy convention which is followed by all coroutine builders, this scope’s coroutineContext property is the same as the context of the coroutine that is running inside this block:
This way, when we see an unqualified coroutineContext reference in code, there is no confusion between the correspondingly named top-level property and a scope’s property, since they are the same at all times by design.
IntelliJ IDEA handily marks the block of code inside coroutine builders with this: CoroutineScope hint which lets us immediately distinguish regular code blocks from the blocks with a different context. Moreover, this new CoroutineScope always has a new Job in its context. So, when you see launch { … } in the source code without an explicit receiver you can quickly tell what scope it is launched in by looking for the outer block marked as this: CoroutineScope.
Since the context and the scope are materially the same thing, we could have launched a coroutine without having access to the scope and without using GlobalScope simply by wrapping the current coroutineContext into the instance of CoroutineScope as shown in the following function:
Do not do this! It makes the scope in which the coroutine is launched opaque and implicit, capturing some outer Job to launch a new coroutine without explicitly announcing it in the function signature. A coroutine is a piece of work that is concurrent with the rest of your code and its launch has to be explicit².
If you need to launch a coroutine that keeps running after your function returns, then make your function an extension of CoroutineScope or pass scope: CoroutineScope as parameter to make your intent clear in your function signature. Do not make these functions suspending:
Suspending functions, on the other hand, are designed to be non-blocking and should not have side-effects of launching any concurrent work. Suspending functions can and should wait for all their work to complete before returning to the caller³.
