Deadlocks in non-hierarchical CSP

It is well-known that programs with shared mutable state protected by locks are prone to deadlocks, but it is less known that programs without shared mutable state, based either on Communicating Sequential Processes (CSP) or based on an actor model can deadlock, too, despite them not using locks at all. They deadlock in a different way, known as communication deadlock.
See, the formal definition of a deadlock is not directly tied to locks. The set of processes (threads/coroutines/actors) is in a deadlock when each one is waiting for the next one in a loop. We’ll see a concrete example soon, but first I need to apologize for not highlighting this issue before.
The stage
During KotlinConf 2018 I gave a talk titled “Kotlin Coroutines in Practice” (video and slides) in which I’ve shown the importance of structured concurrency to build reliable software in practice and gave a glimpse of some advanced concepts of CSP programming style as implemented in kotlinx.coroutines library. In that section of my talk lies a problem. If you write all the code from my presentation verbatim, you are bound to get into a deadlock. Somehow I fell into this trap, thinking it is safe in my case, but no. So let us dissect it.
To start, note that all CSP-like architectures (including actor model) are safe if an application is structured as a data processing pipeline, where incoming messages enter into the system, get processed by different coroutines in sequence, and sent to the outside world at the end. More broadly, the code is trivially deadlock-free as long as it has a hierarchy (or DAG — directed acyclic graph) of coroutines, where higher-level coroutines only send messages to lower-level ones, but not vice versa, and each coroutine receives all incoming messages in one place, reacting to them by sending messages downstream.

However, during my presentation I’ve sketched an architecture with a data processing loop (see my presentation for the explanation of the problem that is being solved). The “Downloader” coroutine is sending locations for download to the pool of “Workers” and is receiving the resulting contents back from them:

The architecture in my presentation is based on three channels: references, locations, and contents . The body of the downloader coroutine has the following communication logic:
while (true) {
select<Unit> {
references.onReceive { ref -> // (1)
val loc = ref.resolveLocation()
...
locations.send(loc) // (2)
}
contents.onReceive { (loc, content) -> ... } // (3)
}
}Downloader receives from the references channel (1), resolves references to locations and sends them to the locations channel (2). It also processes results from workers by receiving from contents channel (3) to update its state. On the other side workers have the following code:
for (loc in locations) { // (4)
val content = downloadContent(loc)
contents.send(LocContent(loc, content)) // (5)
}They receive from locations channel (4) and send downloaded contents to the contents channel (5).
It is hard to follow the logic even in two communicating pieces of code, but in CSP there is a handy way to visualize it. We can represent our system with Communicating Finite State Machines (CFSM). The states correspond to suspension points and transitions to communications:
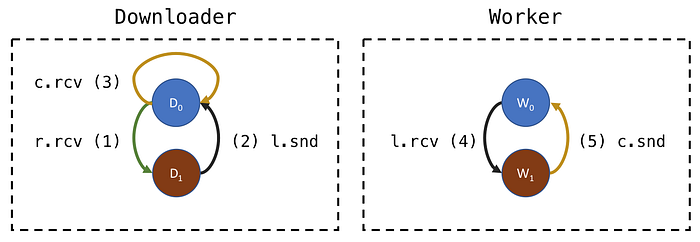
Channel names are abbreviated on the above diagram for brevity, receive operation is abbreviated to rcv, and send to snd. Downloader’s select statement in its main loop corresponds to the state D₀ where it can receive from references channel at (1) (shown as r.rcv) or from contents channel at (3) (shown as c.rcv). When it receives from references, it goes to state D₁, where it waits to send to locations channel at (2) (shown as l.snd).
Deadlock demo
I’ve filled in the missing pieces in the code from presentation with mock data classes, added downloadContent function so that it completes in 10 ms (see the code here) and the main function that just continuously sends requests to downloader’s references channel (here) and runs everything with a 3 second timeout using 4 workers. So there is a complete project that can be run. The correctly working code should process ~1000 requests in those 3 seconds. You can either clone it from a Github or run a single-file version in Kotlin playground here.
When you run this code you see that it processes only 4 requests (it is the number of workers defined in the code) and hangs, timing out after 3 seconds. Moreover, it does so consistently without any randomness whatsoever. It is deterministic, because it is run in a single-threaded runBlocking context.
In order to convince you (and myself) that it is an inherent behavior of this kind of CSP code and not some bug of Kotlin implementation, I also rewrote the same code line-by-line in Go (see here or run in Go playground here, don’t blame me for Kotlinish style of code). Go runtime has a simple deadlock detector that immediately tells the situation for what it is: all goroutines are asleep — deadlock!¹ But what did actually happen?
All workers had completed their initial work and are in state W₁ trying to send to contents channel at (5) back to downloader but it is a rendezvous channel and downloader is not receiving from it right now. Downloader is in state D₁ trying to send to locations channel at (2), but workers are not receiving from it — they are all trying to send. A deadlock indeed — every coroutine is waiting.

Solutions that do not work
It might seem that the problem is in select expression. It is easy to get rid of it here. Instead of having downloader process incoming messages from references and contents channels via select, we can rewrite downloader using an actor pattern as a coroutine that has a single mailbox channel for incoming messages (check the code here or try in it playground here):
for (msg in mailbox) {
when (msg) {
is Reference -> ...
is LocContent -> ...
}
}However, actor-based approach does not avoid the deadlock either and this code hangs as quickly as the original one. You can notice that its communication state-machine is the same.
Another candidates to blame are rendezvous channels — channels without a buffer, since they suspend on trying to send to them without receiver on the other side. But even if we add buffers for both contents and locations, it is still not going to solve the problem. It will become less likely and will take more time to appear (see changes here, playground here). The larger the buffers, the less likely the problem is going to show up, but there is nothing to fundamentally prevent a deadlock situation from happening. Senders still suspend and deadlock when buffers are full².
Unlimited-capacity channels
A definite deadlock-prevention solution is to use buffer with UNLIMITED capacity on at least one channel affected by communication deadlock. You can see the code with unlimited contents channels here and check it out in playground here to verify that it seems to work properly³.
However, by removing the limit on the channel buffer we forfeit the lucrative property of CPS programming style — automatic back-pressure propagation. If the receiver of messages from the channel is slower than the sender, then sender is suspended on full buffer to slow down automatically. With unlimited-capacity channels this is not going to happen and the task of managing back-pressure lies solely on the shoulders of application developer. Failing to manage back-pressure the system may eventually run out of memory, collecting more and more messages in its buffers.
In our case, making locations channels unlimited would completely remove back-pressure management for incoming references, since downloader would quickly send all of them to the locations channel even when all workers are already busy. Using unlimited capacity for contents channel is safer as it only affects the final processing of downloaded contents. However, with unlimited capacity we are at risk that downloader gets overwhelmed by the incoming references and never gets to process downloaded contents⁴. This observation brings us close to the first fully working approach.
Solutions that do work
Let us flip the order of cases in select expression in downloader coroutine so that contents channel get checked first, i.e. so that contents messages (downloads completed by worker pool) have priority over messages in references channel:
select<Unit> {
contents.onReceive { ... }
references.onReceive {
...
locations.send(loc) // (2)
}
}By itself it does not fix the problem (you can verify the code in playground here), but it gives one useful property — downloader would try to send to locations channel at (2) only if no worker was suspended trying to send to contents channel at some moment of time before that. Now, it is enough to give contents channel capacity of at least one to ensure that there is at least one worker that can send its contents at (5) and start receiving from locations again at (4), allowing downloader to proceed, too:
val contents = Channel<LocContent>(1)The working code is here, playground version is here. Notice, how it processes more downloads in those 3 seconds than the previous “solution” with unlimited channel. Moreover, with contents channel processing having highest priority, it is now safe to have unlimited capacity for contents channel. It will never keep more messages in its buffer than the number of workers plus one (why plus one? this is left as an exercise for the reader to show).
There is also an alternative solution that does not use buffered channels at all and works perfectly with channels of any capacity. It doubles down on select to avoid suspending downloader on locations.send(loc), folding this sending operation into a select. It is actually the simplest one to represent and analyze in CFSM model, but I will not go into details now, leaving it for some future story. You can take a look at the corresponding code here and run it in playground here.
Conclusion
Communication loops (non DAG patterns) can and will cause communication deadlocks with channels of limited capacity, unless some deadlock-prevention strategy is used. If you encounter deadlock in your application, do not try to work around it with buffered channels before you understand what is going on or you risk sweeping the problem under the rug.
Feel free to share more working solutions to this particular communication loop deadlock in the comments to this story. The code both in Kotlin and in other CSP/actor runtimes is welcome (give a link, don’t paste the code into the comments, please).
Credits
I’d like to express my gratitude to Alexey Semin who had reported this problem via this github issue and Alexander Gorynin who contacted me in the Kotlin Slack⁵. Also thanks to Simon Wirtz and Sean McQuillan for useful comments on the draft of this post.
UPDATE: The future roadmap
One question you may ask after reading this story: What is the future of channels in Kotlin? They will definitely stay, but they should be considered as “low-level primitives”, building block of higher-level, less error-prone constructs. Read more in the series of posts about Kotlin flows:
Footnotes
¹ ^ Go deadlock detector is much simpler than deadlock-detectors that are typically available for lock-based code (there is one built into JVM, for example). It only detects situation where the progress had stalled globally in the whole application and cannot detect local deadlock in a part of a larger system. Moreover, it is not an accidental oversight — precise local deadlock detector is impossible to implement for this kind of CSP system runtime where channels themselves are regular objects that can be sent anywhere.
² ^ In Go select statement is making a non-deterministic choice (similarly to selectUnbiased function in Kotlin), so with buffers in Go the problem reproduces with lower probability, creating a false sense of safety.
³ ^ Using unlimited capacity is the deadlock-prevention approach that actor-based Akka framework is taking. It gives actors mailboxes with unlimited capacity by default.
⁴ ^ Moreover, unlimited capacity can create arbitrary delays between successful sending of request and its completion.
⁵^ You can also get invite and take part in discussions at slack.kotl.in. If you’ve read this story, then #coroutines channel is the one you want to join.
